








 Paylaş
Paylaş





 1
1

Çağımızın yükselen teknolojisi yapay zekâ, sivil planlamadan sağlık hizmetlerine ve siber güvenliğe kadar tüm endüstrilerde bir dönüşümü vadediyor. Lakin gizlilik, özellikle uyum ve düzenleme söz konusu olduğunda sektörde çözülemeyen bir zorluk olmaya devam ediyor. Hatta pek çok şirket, kişisel verilerin sızdırılması nedeniyle gündeme geliyor.
Bu noktada Apple ve Google gibi pek çok devasa şirketin bu konudan muzdarip olduğunu söylemek mümkün. Hatırlarsanız Apple, Siri kayıtlarının dinlenmesi skandalıyla bir süre gündemden düşmemişti. Nisan ayında Bloomberg, bilişim devi Amazon’un Alexa destekli cihazlardan binlerce saatlik ses kayıtlarını dinlemek için taşeron işçiler kullandığını ortaya çıkarmıştı.
Son dönemlerde bunun gibi binlerce farklı olayın yaşandığını ve pek çok dev firmanın bu olaylarla gündeme geldiğini söyleyebiliriz. Evet, yasalar gizliliği korumak için çalışıyor ancak yeterli değil. Peki yapay zekanın gizlilik sorununu hangi teknikler çözebilir? Gelin, bunlara biraz daha yakından bakalım.
Yapay sinir ağları ve güvenlik açıkları:

İnsan beyni ve sinir sisteminden esinlenerek oluşturulmuş bu modelde, ilk katman girişi son katman ise çıkışı temsil eder. Ortada bulunan katmanlar ise gizli katmanlardır ve her katmanda belirli sayıda nöron (neuron/sinir hücresi) bulunur. Çoğu yapay zekâ sisteminin merkezinde bulunan sinir ağları, diğer nöronlara sinyal ileten katmanlarda düzenlenmiş fonksiyonlardan oluşur.
Bu sinyaller, katmandan katmana geçer ve her bağlantının sinaptik kuvvetini ayarlayarak ağı yavaşça ayarlar. Sinir ağları ham görüntüleri, videoları sesi ve metni almaz. Daha ziyade alıştırma yapılarından örnekler; tek sayılar, vektörler ve matrisler gibi cebirsel olarak çok boyutlu dizilere dönüştürülür. Tüm bunları kapsayan dördüncü bir varlık türüyse geçerli doğrusal dönüşümlerin açıklamalarına eklenir.
Bu dönüşümlere rağmen potansiyel olarak hassas bilgileri, sinir ağının çıktılarından ayırt etmek çoğu zaman mümkündür. Ayrıca veri kümelerinin kendileri de savunmasızdır çünkü genelde gizlenmezler ve veri ihlallerine karşı savunmasız olan merkezi depolarda depolanırlar.

Şimdiye kadar en yaygın tersine mühendislik makine öğrenimi olarak bilinen “membership inference attack” ve bu teknikle bir saldırgan, hedef modelin eğitildiği yapıya ait olup olmadığını belirler. Anlaşılacağı üzere hassas bilgileri bir veri kümesinden kaldırmak, yeniden çıkarılamayacağı anlamına gelmez çünkü yapay zekâ örnekleri yeniden oluşturmada son derece başarılıdır.
Bir çalışmada Wisconsin Üniversitesi'nden araştırmacılar, tıbbi dozajı tahmin etmek üzere eğitilmiş bir makine öğrenme modelinden hastaların genomik bilgilerini aldılar. Bir diğer çalışmada ise Carneige Mellon ve Wisconsin-Madison Üniversitesi araştırmacıları, yüz tanıma yapmak için eğitilmiş bir modelden belirli kafa çekimi görüntülerini yeniden oluşturmayı başardılar.
Daha karmaşık bir veri çıkarma saldırısı, üretilen örnekleri ve gerçek dünyadaki örnekleri birbirinden ayırmaya çalışan ve birbirine zıt şekilde çalışan iki parçalı yapay zekâ sistemleri olan generative adversarial networks’ü (GAN) kullanır. Bu sistemde generator sürekli yeni data üretirken discriminator ise generator tarafından üretilen datanın gerçekliğini kontrol eder.
Birleşik öğrenme:
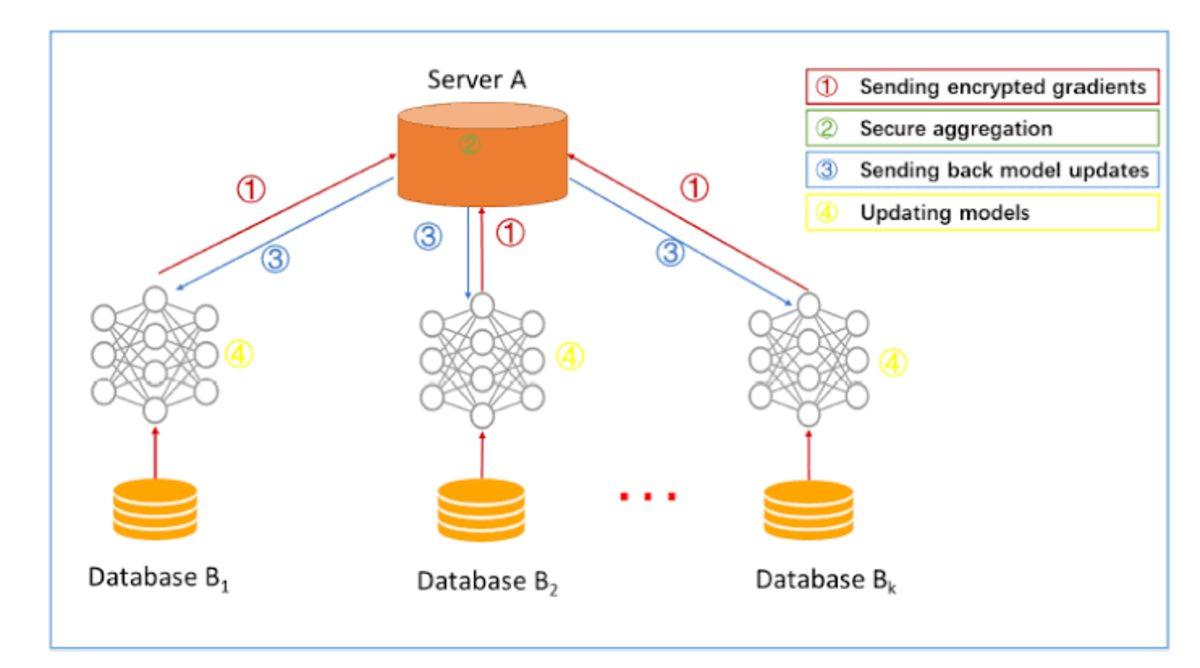
Basit bir şekilde tanımlamak gerekirse birleşik öğrenme, yapay zekâ algoritmasını merkezi olmayan aygıtlar veya bu örnekleri değiştirmeden veri örnekleri tutan sunucular (yani düğümler) üzerinden eğiterek, birden fazla tarafın verileri serbestçe paylaşmadan ortak bir makine öğrenme modeli oluşturmasını sağlayan bir tekniktir. Bu teknik, yerel veri örneklerinin yaygın bir şekilde dağıtıldığını varsayan klasik merkezi olmayan yaklaşımların tam zıttıdır.
Merkezi bir sunucu, algoritmanın adımlarını düzenlemek ve bir referans saat olarak hareket etmek için kullanılabilir veya düzenleme P2P (peer-to-peer) şeklinde olabilir ki bu durumda sunucu yok demektir. Buna rağmen yerel modeller, yerel veri örnekleri üzerinde eğitilir ve ağırlıklar küresel bir model oluşturmak için bazı frekanslarda modeller arasında değiştirilir.
Yinelemeli bir süreç olan bu teknikte yerel modeller, her bir düğümde bir dizi potansiyel model güncellemesi üretmek üzere düğümlerde eğitilir. Daha sonra yerel güncellemeler tek bir genel güncellemede toplanarak işlenir ve genel modele uygulanır.
Birleşik öğrenme, bu alanda öncü olan Google tarafından üretime yerleştirilmiştir. Google, bu tekniği kişiselleştirme için Gboard’da iOS ve Android cihazlarının on milyonlarcasında kullanıyor.
Tabii ki hiçbir teknik kusursuz değildir ve birleşik öğrenme, öğrenme sürecinde düğümler arasında sık iletişim gerektiriyor. Makine öğrenme modellerinin parametre alışverişinde bulunabilmesi için önemli miktarda işlem gücüne ve belleğe ihtiyaç vardır. Diğer zorluklar arasında eğitim örneklerinin denetlenememesi gibi değişkenler bulunmaktadır.
Diferansiyel gizlilik:

Henüz yeni sayılabilecek bir siber güvenlik yaklaşım modeli sayılabilecek diferansiyel gizlilik, teknoloji şirketlerinin bireysel kullanıcıların gizliliğini korurken, kullanıcı alışkanlıkları hakkında bilgiler toplayabilmesine de olanak tanır. Yani bu modelde nadir detayların ezberlenmesi önlenir ve nihai kişi hakkındaki bilgilerin çıkarılamayacağını garanti edilir.
Teknoloji devi Apple, 2017 yılından beri popüler emojilerini, Safari’deki medya oynatma tercihlerini ve daha fazlasını tanımlamak için bir çeşit diferansiyel gizlilik kullanıyor ve şirket en güncel iOS sürümünde (iOS 13) bunu birleşik öğrenme ile birleştirdi. Her iki teknik de Siri’nin sunduğu sonuçların yanı sıra Apple’ın QuickType klavyesi ve iOS’un Found In Apps uygulamalarının iyileştirilmesine yardımcı oluyor.
Ne yazık ki diferansiyel gizlilik de mükemmel değil. Bu teknikte temel verilere, girişe, çıkışa veya parametrelere entegre edilen gürültü, genel modelin performansını etkiler. Daha önce yapılan bir çalışmada araştırmacılar, eğitim veri setine gürültü eklendikten sonra tahmin doğruluğunun %94,4’ten %24,7’ye düştüğünü belirttiler.
Homomorfik şifreleme:

Homomorfik şifreleme yeni bir şey değil çünkü ilk şema, IBM araştırmacısı Craig Gentry tarafından 2009 yılında geliştirildi. Temel olarak bu teknik, şifreli metinlerde hesaplama yapılmasına olanak sağlayan, şifresi çözüldüğü zaman düz metin üzerinde yapılmış gibi işlemlerin sonucuyla eşleşen şifreli bir sonuç üreten bir şifreleme şeklidir ve dış kaynaklı depolama ve hesaplamanın gizliliğini korumak için kullanılır.
Intel’in IoT grubunun başkan yardımcısı Jonathan Ballon, bu yılın başlarında yapılan bir röportajda “MRI görüntülerimi gönderirsem, doktorumun onları hemen görebilmesini ancak başka hiç kimsenin görmemesini istiyorum” demişti. “Homomorfik şifreleme, modelin kendisinin de şifrelenmesini sağlar. Bu yüzden bir şirket, bu modeli genel bir buluta koyabilir ve bulut sağlayıcısının modellerin neye benzediğine dair hiçbir fikri yoktur.”
Pratikte, homomorfik şifreleme çalışmaları henüz modern donanımı tam olarak kullanamamaktadır ve en azından geleneksel modellerden daha yavaş bir büyüklük düzenindedir. Ancak hızlandırılmış bir şifreleme kütüphanesi olan cuHE gibi daha yeni projeler, önceki uygulamalara göre çeşitli şifreleme görevlerini 12 ila 50 kat arasında hızlandırabiliyor. Bu noktada Facebook’un PyTorch makine öğrenme yapısı ve TensorFlow üzerine kurulmuş olan PySyft ve tf-encrypted gibi kütüphaneler son aylarda büyük adımlar attı.
Birkaç ay önce Intel araştırmacıları HE-Transformer'ın halefi olan nGraph-HE2'yi, yerel etkinleştirme işlevlerini kullanarak standart, önceden eğitilmiş makine öğrenme modellerinde çıkarım yapılmasını sağlamak için önerdiler.
Yayınlanan bir makalede, iş hacminde skaler kodlama (sayısal bir değerin bir bit dizisine kodlanması) açısından çalışma süresinin 3 kat ile 88 kat daha hızlı olduğu ve ek çarpma ve ekleme optimizasyonlarının da 2,6 kat ile 4,2 kat hızlı olduğunu bildirildi.
Daha gidilecek çok yol var:

Yeni teknikler, yapay zekâ ve makine öğreniminin doğasında bulunan bazı gizlilik sorunlarını çözebilir ancak daha yolun çok başındalar ve birçok eksiklikleri bulunuyor.
Birleşik öğrenme, öğrenme sürecinde düğümler arasında sık iletişim gerektiriyor ve eğitim örneklerinin denetlenmensi oldukça güç. Öte yandan diferansiyel gizlilikteyse temel verilere, girişe, çıkışa veya parametrelere entegre edilen gürültü, genel modelin performansını etkiliyor ve doğrulukta düşüşlere neden oluyor. Homomorfik şifrelemeye gelince, biraz yavaş ve sayısal olarak çok emek istiyor.

Yine de gelecekte yapay zekâ teknolojisinde ne gibi gelişmeler yaşanacağını ve gizlilik sorunlarının nasıl çözüleceğini merak ediyoruz. Nasıl gelişmeler olacağını ise ancak yaşayıp hep birlikte görebileceğiz.





![XP'den 11'e Kadar Olan Tüm Windows Sürümleri Karşılaştırma Testine Girdi: İşte Sonuçlar! [Video]](https://imgrosetta.webtekno.com/file/643316/643316-640xauto.jpg)