







 Paylaş
Paylaş





 0
0

Google DeepMind tarafından geliştirilen FACTS Benchmark Suite, yapay zekâ sohbet botlarının gerçek hayattaki doğruluk seviyesini ölçmek için hazırlandı. Testler; bilgi tabanlı sorular, uzun metinler, web verileri ve görsel yorumlama gibi alanları kapsıyor.
Sonuçlar oldukça çarpıcı: En iyi performansı gösteren modeller bile en fazla %69 doğruluk oranına ulaşabiliyor. Yani yapay zekâların verdiği her üç yanıttan biri yanlış, eksik ya da yanıltıcı olabiliyor.
İçerikten Görseller

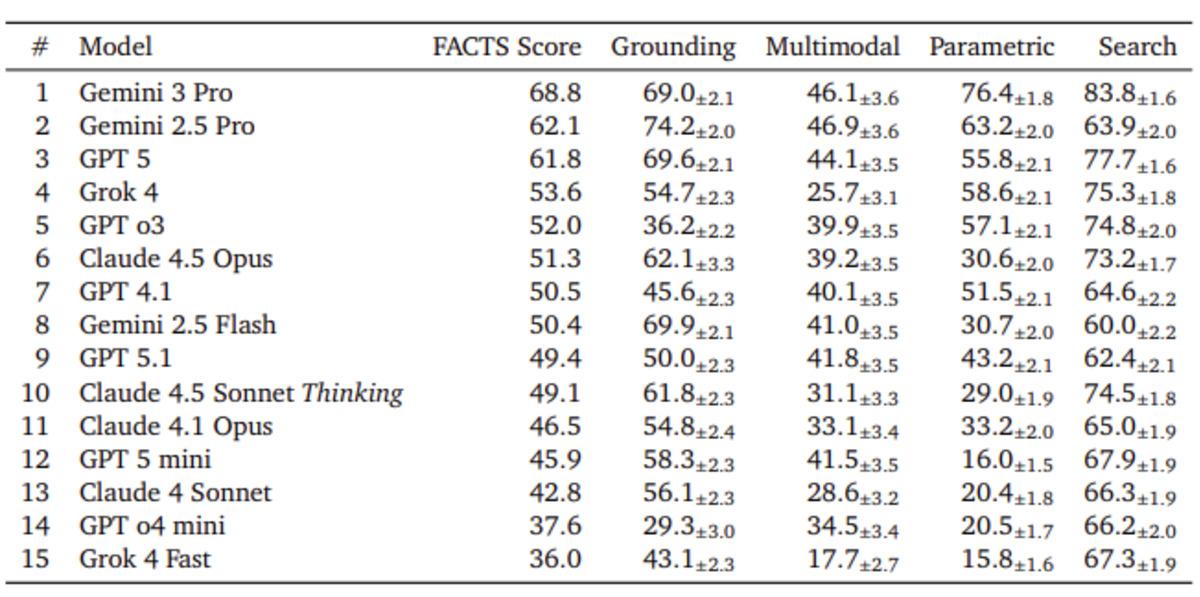
Bu tablo, AI’ın son yıllarda hızla yaygınlaşmasına rağmen özellikle sağlık, hukuk ve finans gibi kritik alanlarda hâlâ ciddi riskler taşıdığını gösteriyor. Akıcı ve ikna edici yanıtlar, her zaman doğru bilgi anlamına gelmiyor.
Geçmişte de “halüsinasyon” sorunlarıyla gündeme gelen AI modelleri için bu çalışma önemli bir hatırlatma niteliğinde. Uzmanlara göre yapay zekâ, güçlü bir yardımcı olmaya devam edecek ancak yakın gelecekte de insan denetimi olmadan tam güvenilir bir kaynak hâline gelmesi zor görünüyor.















