







 Paylaş
Paylaş





 0
0

Türkçede transkripsiyon doğruluğunu ölçmenin kriterleri ve yöntemleri, kültürel lehçeleri ve aksanları ne kadar iyi yakaladığını da içerir. İster İstanbul'un net telaffuzu, ister Karadeniz bölgesinin hızlı, kelime yutma ritmi olsun, her biri otomatik transkripsiyon sistemleri için benzersiz birer test alanıdır.
Günümüzde podcast üreticileri, gazeteciler, hukukçular, akademisyenler ve sosyal medya içerik üreticileri, kayıtlarını hızlı ve doğru biçimde yazıya dökebilmek için otomatik sistemlere güveniyor. Ancak bu sistemlerin performansı her zaman aynı değil. Bir model, İstanbul Türkçesi’nde mükemmel sonuç verirken Karadeniz aksanında beklenmedik hatalar yapabiliyor.
İçerikten Görseller



Bu yazıda, Türkçe transkripsiyon doğruluğunu ölçmek amacıyla yaptığımız detaylı benchmark çalışmasının metodolojisini, bulgularını, örneklerini ve pratik ipuçlarını adım adım paylaşacağız.
Test tasarımı ve ölçüm kriterleri dahil olmak üzere metodoloji nedir?
Test tasarımı ve ölçüm kriterlerini içeren metodoloji, yalnızca "modeli çalıştır ve sonuçları al" yaklaşımından ibaret olamaz; aksine, güvenilirliği sağlamak için her adım dikkatlice planlanmalıdır. Bu adımlar arasında veri kümesi oluşturma, gürültü senaryoları ve model seçimi yer alır.
1. Veri seti oluşturma
Türkçe’deki aksan çeşitliliğini yansıtmak için dört ana grup belirlendi:
- İstanbul Türkçesi – Net artikülasyon, haber spikeri tarzı kayıtlar, resmi dil kullanımı.
- Karadeniz Aksanı – Hızlı tempo, hece yutma, bazen ünlü harflerin daralması.
- Doğu Anadolu Aksanı – Ses uzatma, bazı ünlü değişimleri, melodik intonasyon.
- Arapça Etkili Aksan – Kelime sonlarında tonlama değişiklikleri, ekleme/çıkarma eğilimleri.
Her aksan için:
- 30 dakikası stüdyo kaydı,
- 30 dakikası doğal ortam konuşması (pazar, sokak, kafe gibi) olmak üzere toplam 1 saatlik kayıt toplandı. Böylece 4 aksan için 4 saatlik ham ses verisi elde edildi.
2. Gürültü senaryoları
Gerçek hayat koşullarını simüle etmek için her ses kaydına dört farklı senaryo uygulandı:
- Temiz kayıt – Stüdyo kalitesinde, minimum yankı.
- Hafif gürültü – Arka planda düşük seviyede ortam sesi (ör. bilgisayar fanı, hafif trafik).
- Yoğun gürültü – Pazar yeri, kalabalık kafe, araç kornaları gibi dikkat dağıtan sesler.
- Düşük kaliteli cihaz kaydı – Eski telefon mikrofonu veya düşük bit hızı.
Böylece, toplamda 4 aksan × 4 senaryo = 16 farklı test ortamı oluşturuldu.
3. Model seçimi ve test döngüsü
Üç farklı Türkçe destekli otomatik transkripsiyon modeli seçildi:
- Model A – Genel amaçlı, hızlı işleme süresi.
- Model B – Gürültüye dayanıklı, yapay zekâ destekli hata düzeltme.
- Model C – Aksan adaptasyonu için ek eğitilmiş sürüm.
Her ses dosyası üç modelde üçer kez çalıştırıldı. Ortalama WER (Word Error Rate) ve CER (Character Error Rate) değerleri alındı.
4. Ölçüm metrikleri
- WER: Yanlış kelime / toplam kelime oranı.
- CER: Yanlış karakter / toplam karakter oranı.
- Not: WER yüksekse anlam bütünlüğü bozulur; CER yüksekse yazım hataları artar.
Türkçe'de Transkripsiyon Doğruluğu Sonuçlarına İlişkin Bulgular Nelerdir?
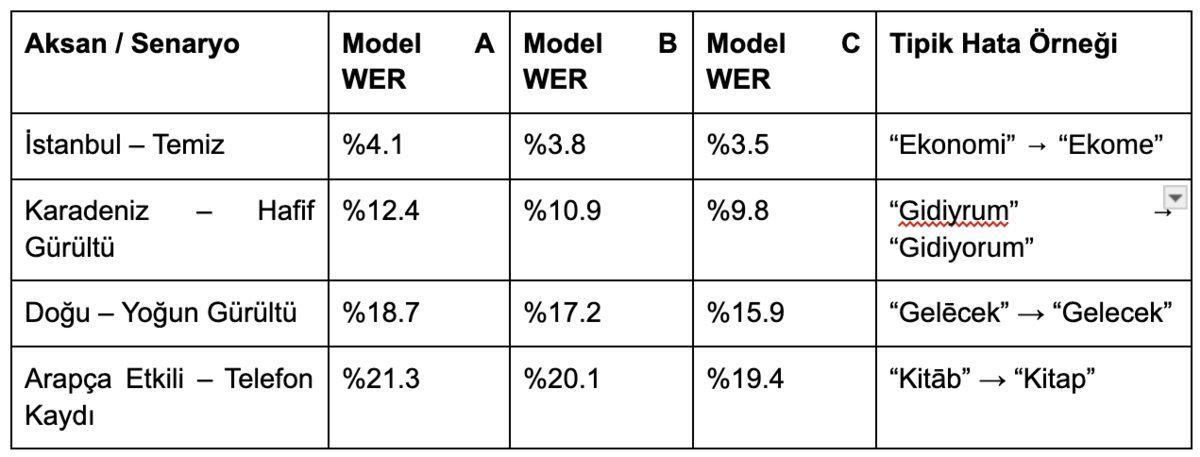
Temiz kayıtlar İstanbul Türkçesi’nde %95+ doğruluk verirken, yoğun gürültü ve bölgesel aksanlar bu oranı ciddi biçimde düşürdü. Karadeniz ve Arapça etkili aksanlar, özellikle hızlı konuşma ve ekleme/çıkarma eğilimleri nedeniyle hata oranını yükseltti.
Ethnologue'a göre Türkiye, 19 yaşayan yerli ve 25 yaşayan yabancı dile ev sahipliği yapmaktadır. Transkripsiyonun doğruluğu, tabloda gösterildiği gibi dil türüne göre değişmektedir:
İşte bazı örnek cümleler ve hata türleri:
İstanbul Türkçesi
- Orijinal: “Bugün hava gerçekten çok güzel.”
- Hata: “Bugün hava gerçek ten çok güzel.” (Boşluk hatası)
Karadeniz Aksanı
- Orijinal: “Bu sene fındık az oldu.”
- Hata: “Bu sene fındı kaz oldu.” (Kelime birleştirme)
Doğu Anadolu Aksanı
- Orijinal: “Yarın misafirler gelecek.”
- Hata: “Yarın misafirler gel ecek.” (Yanlış boşluk)
Arapça Etkili Aksan
- Orijinal: “Ahmet yeni kitabı aldı.”
- Hata: “Ahmet yeni kit abi aldı.” (Ünlü kırılması)
Aksanları Geliştirmek İçin İpuçları Nelerdir?
Türkçede aksanları geliştirmenin yolları aksana bağlıdır. Örneğin, İstanbul Türkçesinde telaffuzunuzu netleştirmeniz gerekirken, Karadeniz aksanında tempoyu düşürmeyi düşünebilirsiniz. İşte detaylar:
İstanbul Türkçesi
- Net telaffuz: Uzun kelimelerde heceleri belirgin söylemek.
- Kısa cümleler: Anlamı iki kısa cümleyle bölmek.
- Sabit mikrofon mesafesi: Ses seviyesi dalgalanmaz.
Karadeniz Aksanı
- Tempo düşürme: Modelin kelime sınırını anlaması için duraklamalar.
- Standart telaffuz denemesi: Yerel söyleyişleri azaltmak.
- Gürültü filtreleme: Hafif gürültü bile hatayı artırır.
Doğu Anadolu Aksanı
- Ses uzatmalarını sınırlama: “Gelēcek” yerine “gelecek”.
- Ünlü uyumu: Beklenmedik ünlü değişimlerini azaltma.
- Ön test: Modelin sese adaptasyonu.
Arapça Etkili Aksan
- Harf ekleme/çıkarma önleme: Standart telaffuza yakın konuşma.
- Tonlama düzenleme: Kelime sonlarını yumuşatma.
- Harici mikrofon: Telefon mikrofonlarındaki bozulmayı azaltma.
Sonuç: Genişletilmiş Değerlendirme
Türkçedeki aksan çeşitliliği, otomatik transkripsiyon teknolojileri için iki ucu keskin bir gerçeklik yaratır: bir yandan önemli bir zorluk, diğer yandan da büyük bir geliştirme fırsatı.
Sonuç olarak, doğru model, doğru kayıt tekniği ve aksana özgü bir strateji, çoğu senaryoda %90 veya daha yüksek bir doğruluk oranına ulaşır. Bu eşik, metnin anlamsal bütünlüğünü korumakla kalmaz, aynı zamanda içerik üretiminde zaman ve maliyet tasarrufu sağlayarak manuel düzenleme ihtiyacını en aza indirir.
Anadolu Ajansı'nın haberine göre, Türkiye'nin yapay zekadaki payı 600 milyon doları aştı ve çok sayıda model hayata geçirildi. Türkçe transkripsiyonda başarıya giden yol, tek bir "mükemmel" model bulmaktan değil, veri, teknoloji ve insan faktörünün bilinçli bir şekilde bütünleştirilmesinden geçer.















