Paylaş
Paylaş





 1
1

Yapay zekâ modelleri genelde ne kadar güncel bilgiye sahip olduklarıyla gündeme geliyor. Ancak bu kez durum biraz farklı. Araştırmacılar, modern dünyayı bilmemesi için özel olarak tasarlanmış bir yapay zekâ modeli geliştirdi. Yani bu model teorik olarak interneti, iPhone’u, YouTube’u veya sosyal medyayı bilmiyor.
Talkie adı verilen bu model, Nick Levine, David Duvenaud ve Alec Radford tarafından tanıtıldı. 13 milyar parametreli yapay zekâ, 1931 öncesine ait İngilizce metinlerle eğitildi. Bu yüzden ona “1930’dan gelmiş gibi konuşan yapay zekâ” demek pek de yanlış olmaz.
İçerikten Görseller




Talkie, modern internet yerine eski kitaplarla eğitildi
SORU: 2026 yılında "akıllı telefon" adında bir tüketici teknolojisi ürünü hangi özelliklere sahip olurdu?
Talkie-1930: Elde tutulan küçük yuvarlak bir kutu biçiminde, bir vericisi ve kulak şekline benzer bir alıcısı olurdu. Kutunun içinde bir diyafram bulunur ve buna bir ağızlık takılı olurdu. Tüm cihaz yaklaşık bir kol saati büyüklüğünde olurdu. Alıcı bir kancaya asılır ve onunla verici arasındaki bağlantı esnek bir kablo aracılığıyla sağlanırdı. Akıllı telefon esas olarak kişisel iletişim için kullanılırdı ve konuşmacının, cihazdan yaklaşık elli fit uzaklıktaki bir odada sesini duyurmasını sağlardı. Günlük konuşma tonunu koruyarak ses yeniden üretilirdi. Akıllı telefon, sağır kişiler için ve ayrıca konuşmacıların ile aktörlerin bir binanın her köşesinde kendilerini net biçimde ifade edebilmeleri açısından büyük fayda sağlardı. Ayrıca askeri operasyonlarda da yararlı olur, generallerin kurmay subaylarıyla kolayca iletişim kurmalarını mümkün kılardı.
Siz de denemek isterseniz buraya tıklayabilirsiniz.
Talkie’nin eğitiminde kitaplar, gazeteler, dergiler, bilimsel yayınlar, patentler ve hukuk metinleri kullanıldı. Toplam eğitim verisinin 260 milyar token olduğu açıklandı. Yani model, bugünkü internet verileri yerine büyük ölçüde tarihî arşivlerden beslenmiş durumda.
Araştırmacılar özellikle 1930 yılını seçti çünkü bu dönemden önce yayımlanan birçok İngilizce eser kamu malı kapsamına giriyor. Böylece model, günümüz web siteleriyle değil; eski dünyanın dili, bilgisi ve bakış açısıyla eğitilmiş oluyor.
Amaç sadece “geçmişten biriyle konuşmak” değil
İlk bakışta bu proje kulağa eğlenceli bir deney gibi geliyor. Sonuçta modern dünyayı bilmeyen bir yapay zekâya “iPhone nedir?” diye sormak epey ilginç olabilir. Ancak Talkie’nin asıl geliştirilme nedeni bundan çok daha ciddi.
Araştırmacılar, Talkie ile yapay zekâ modellerinin bilgiyi nasıl öğrendiğini, nasıl genelleme yaptığını ve eğitim verisindeki sızıntılardan nasıl etkilendiğini incelemek istiyor. Yani bu model, “cahil” olduğu için değil; kontrollü biçimde geçmişte bırakıldığı için değerli.
Modelin iki farklı sürümü var
Talkie’nin temel sürümü talkie-1930-13b-base adıyla yayımlandı. Bu sürüm, 1931 öncesi metinlerle eğitilen ana model olarak karşımıza çıkıyor. Bir de kullanıcılarla daha doğal sohbet edebilmesi için hazırlanan talkie-1930-13b-it sürümü bulunuyor.
Sohbet odaklı sürüm; eski görgü kuralları kitapları, ansiklopediler, mektup yazma kılavuzları ve benzeri kaynaklardan çıkarılan örneklerle eğitildi. Böylece model, sadece tarihî bilgiye sahip olmakla kalmıyor, aynı zamanda sorulara daha anlaşılır yanıtlar verebiliyor.
Yine de modern dünyadan tamamen habersiz değil
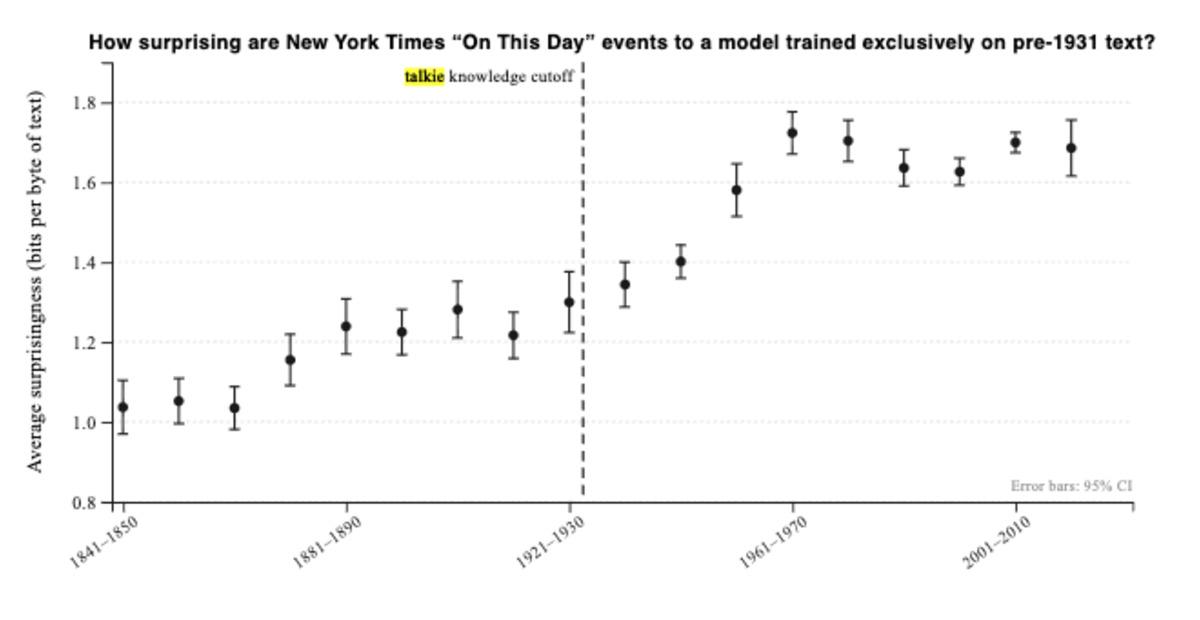
İşin ilginç tarafı, Talkie’nin 1930 sonrasını hiç bilmemesi gerekirken bazı modern tarih bilgilerine ulaşabildiği görülmüş. Bunun nedeni ise veri sızıntısı. Yani yanlış tarihli metinler, sonradan eklenen notlar veya modern açıklamalar eski veri setinin içine karışmış durumda.
Araştırmacılar, önceki Talkie sürümünün Franklin D. Roosevelt ve New Deal gibi 1930 sonrası konularda bilgi sahibi olabildiğini söylüyor. 13 milyar parametreli yeni sürümde de II. Dünya Savaşı, Birleşmiş Milletler ve Almanya’nın bölünmesi gibi bazı bilgiler ortaya çıkabiliyor.
Eski metinleri yapay zekâya okutmak pek kolay değil
Talkie projesindeki en büyük sorunlardan biri, eski metinlerin bilgisayar ortamına aktarılması. Çünkü 1930 öncesi kaynakların büyük bölümü dijital olarak doğmadı. Kitapların, gazetelerin ve belgelerin taranıp metne çevrilmesi gerekiyor.
Bu noktada OCR adı verilen metin tanıma teknolojileri devreye giriyor. Ancak eski sayfa düzenleri, yıpranmış baskılar ve düşük kaliteli taramalar nedeniyle bu sistemler hata yapabiliyor. Araştırmacılar da bu yüzden tarihî metinleri daha doğru okuyabilecek özel sistemler üzerinde çalışıyor.
Talkie açık kaynak olarak kullanılabiliyor
Talkie yalnızca kapalı kapılar ardında test edilen bir araştırma projesi değil. Model, GitHub ve Hugging Face üzerinden geliştiricilerin erişimine açılmış durumda. Yani yeterli donanıma sahip olan kullanıcılar modeli indirip deneyebiliyor.
Tabii bunun için sıradan bir bilgisayar pek yeterli değil. Modeli çalıştırmak için Python, PyTorch ve CUDA destekli güçlü bir ekran kartı gerekiyor. Ayrıca model dosyaları da oldukça büyük; bu yüzden Talkie daha çok geliştiricilere ve araştırmacılara hitap ediyor.
Daha büyük bir “geçmiş yapay zekâsı” da yolda
Araştırmacılar, Talkie’nin şu anda bildikleri en büyük “vintage” dil modeli olduğunu söylüyor. Ancak proje burada bitmeyecek. Ekip, GPT-3 seviyesine yaklaşan daha büyük bir model üzerinde de çalıştıklarını açıkladı.
Gelecekte tarihî metin havuzunun 1 trilyon tokenın üzerine çıkarılması hedefleniyor. Bu gerçekleşirse modern dünyayı bilmeyen ama çok daha güçlü bir yapay zekâ modeliyle karşılaşabiliriz. Yani bir gün gerçekten “1930’lardan gelmiş” gibi konuşan dev bir yapay zekâ görebiliriz.